Defining lader features
<< lader home
One of the important elements to achieve good accuracy with lader is to define useful features for parsing and reordering.
Once you understand the general idea of how the parser works (e.g. by reading the paper), the feature set for lader can be defined easily using feature templates.
In general, you will want to define features over sequences of words or tags, but it is also possible to define features over parse trees if you have a parser available.
Features are defined separately over each set of annotations in a format similar to the following:
seq=...|seq=...|seq=...|cfg=...
In this case, we have three sets of features over sequences, and one over cfgs.
The number and type of features we define depends on the number of annotations we are using, as described in the example training script.
How we fill in each of these annotation strings is different for sequence and CFG features, and I will explain more below.
Sequence Feature Functions
A single sequence feature set definition takes the following form, defining dictionaries and feature templates:
seq=[DICT0],[DICT1],...,[FEAT0],[FEAT1],[FEAT2],...
DICT0, DICT1, etc. are paths to scored dictionaries (phrase tables) that can be referenced by later features.
Each entry takes the form "dict=/path/to/dictionary.txt".
Dictionaries can be referenced either using the absolute path, or the relative path from the model file.
FEAT0, FEAT1, etc. are feature templates.
A feature template takes the form "NAME%VAR1%VAR2%VAR3...".
NAME is the name of the feature, which can be set arbitrarily.
%VAR1, %VAR2, etc. are variable definitions that will be set based on the properties of a node of the parse tree.
Below is a list of variable types that can be used and the values that they will take for the node in the picture below.
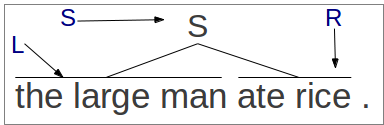
- Word Features: Each word feature is expressed as %XY, where X is the identity of a span, and Y is the position of the word with regards to the span. X can take the following values.
- S: Span covered by the current node. In the example, marked by the blue "S" and covering "the large man ate rice".
- L: Span covered by the left child (only active for non-terminal nodes). This is the blue "L" covering "the large man".
- R: Span covered by the right child (only active for non-terminal nodes). This is the blue "R" covering "ate rice".
Y can take the following values:
- L: The leftmost word in the span. "%RL" in the example above will be "ate".
- R: The rightmost word in the span. "%RR" in the example above will be "rice".
- B: The word before a span. "%RB" in the example above will be "man".
- A: The word after a span. "%RA" in the example above will be ".".
- Span Length Features: The features "%SN" "%LN" "%RN" will return the length of each of the corresponding spans. Above, "5", "3", and "2" respectively.
- Symbol Features: The only symbol feature is "%ET", which indicates the type of node. This will be "S" for "straight" in the example above, but can also be "I" for inverted, "F" for forward non-terminal, or "R" for reverse non-terminal.
- Balance Features: Features that compare the two child nodes "%CD" "%CB" and "CL". These return the difference in length between the two sides, the absolute value of the difference in length between the two sides, or which side is longer. Above, these values will be "-1" (2-3), "1" (abs(2-3)), and "L" (because the left side is longer).
- Dictionary Features: Features that look up whether a span exists in a dictionary, and optionally what the feature value is. For example the feature "%QLE0" is an indicator feature asking whether the left span ("L") exists ("E") in dictionary 0 ("0"). In addition, any feature template including "%QL#01" will take the value of feature 1 in dictionary 0 when matching the left span.
Now, an example of the actual features that we found to be useful in our experiments. Note that we intersected all features with the node type, so entirely different feature values were learned for straight and inverted non-terminals and terminals.
- LL%SL%ET Leftmost word of the span, intersected with node type ("LL||the||S")
- RR%SR%ET Rightmost word of the span, intersected with node type ("RR||rice||S")
- LR%LR%ET Rightmost node of the left span, intersected with node type ("LR||man||S")
- RL%RL%ET Leftmost node of the right span, intersected with node type ("RL||ate||S")
- O%SL%SR%ET Outer two words of the span, intersected with node type ("O||the||rice||S")
- I%LR%RL%ET Words on the boundary of the two children, intersected with node type ("I||man||ate||S")
- Q%SQE0%ET Whether the span exists in the phrase table, intersected with node type ("Q||S" = 1 (if exists))
- Q0%SQ#00%ET, Q1%SQ#01%ET, Q1%SQ#01%ET First, second, and third features in the phrase table, intersected with node type ("Q0||S" = f_0(S)..)
- CL%CL%ET Whether the left or right span is longer, intersected with node type ("CL||L||S")
- B%SB%ET Word before the span, intersected with node type ("B||<s>||S")
- A%SA%ET Word after the span, intersected with node type ("A||.||S")
- N%SN%ET Length of the span, intersected with node type ("N||5||S")
- BIAS%ET A feature that is always active, intersected with node type ("BIAS||S")
CFG Feature Functions
CFG feature functions are defined over a parse tree, and are quite simple compared to sequence features.
They are defined over spans (like the word features above), and take the value of the constituent label in the parse tree for the span.
If there is no constituent that corresponds to the span, they will take the value "X."
Examples of the features used in the paper are below:
- LP%LP%ET, RP%RP%ET, SP%SP%ET Constituent labels for the left, right, and full spans.
- TP%SP%LP%RP%ET The intersection of labels for each of the spans
<< lader home