このページはKyTeaの単語分割・タグ推定で用いられる学習法や特徴量を説明します。
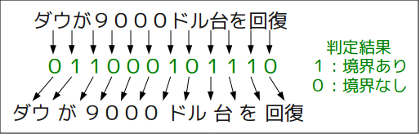
単語分割はポイントワイズで行われます。 すなわち、各文字間に単語境界が存在するかどうかを個別に判定し、他の境界の判定を情報として利用しません。 この手法を採用することにより、部分的にアノテーションされたコーパスを使っても効率的な学習ができます。
各文字間の周りの情報を特徴量とし、この特徴量を用いて線形分類器を学習し、学習された重みで新しいデータを解析します。 単語分割に用いられる特徴量は文字n-gram、文字種n-gram、単語情報の3種類があります。
文字n-gramは判定点の周りの文字を特徴量として利用する。 これに関わる設定として、n-gram長の上限で「-charn」と、利用する文字の窓幅「-charw」があります。 以下の図は-charn=3,-charw=2の場合の一例を示す。

文字自体のn-gramに加え、文字の種類のn-gram情報も用います。 文字種は「漢字」「カタカナ」「ひらがな」「ローマ字」「数字」「その他」に分かれます。 文字n-gramと同じように、n-gram長の上限「-typen」と窓幅「-typew」を指定することができます。
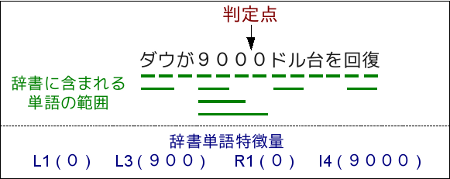
最後に、辞書に含まれている単語が判定点を開始点とする単語があるかどうかを表す特徴量(R)、辞書に含まれている単語が判定点を終了点とする単語があるかどうかを表す特徴量(L)、境界自体が単語に含まれているかを表す特徴量(I)があります。 それぞれの辞書単語特徴量は単語の長さによって区別されます。 例えば、分割境界を終了点とする4文字の単語が存在する場合、この事実を表す特徴量は「L4」となります。 また、「-dicn」は辞書単語の長さの上限を指定し、-dicn=4の場合では単語の長さが5以上であっても「L4」「R4」「I4」となります。 以下の図は辞書単語の一例です:
単語境界の推定が終わってからタグ推定が行われます。 タグ推定は単語分割と同じくポイントワイズで行われ、各単語のタグは他の単語のタグを参考にせずに推定します。 タグ推定には個別モデルと全体モデルという2種類のモデルがあります。
単語の種類によってタグが以下のように推定されます:
学習時に-globalと指定されたタグは全体モデルで推定されます。 全体モデルは単純に全ての単語に対して1つのモデルを学習するため、単語が既知語であっても未知語であっても、そのモデルに基づいて推定されます。 モデルの素性は論文に詳しく書いています。 基本的には文字n-gramと文字種n-gramに加えて、その単語自体の文字と文字種や、辞書に現れているかどうかなどの情報を利用しています。
KyTeaホームに戻る
Last Modified: 2011-4-26 by neubig